- Published on
数据库 | Zilliz 向量数据库模型选择和字段构建
问题

解决思路
向量模型筛选条件:和
- 可在线调用,无需自己部署。
- 开源,可本地部署,将数据向量后传输到 Zilliz 云端。
- 准确度,优先级排后,可用 reranker 模型做二筛。
模型选择难点:各大厂的开源模型和可在线调用的模型不互通。
筛选结果:Jina AI
- 官网:https://jina.ai/
有免费 API 可供测试。
- jinaai/jina-embeddings-v3 · Hugging Face: https://huggingface.co/jinaai/jina-embeddings-v3
- 配置参数需要注意的是检索用
retrieval.query,将长文向量化用retrieval.passage max_length=8192truncate_dim Supported dimensions are [32, 64, 128, 256, 512, 768, 1024]task = 'retrieval.query', 'retrieval.passage', 'separation', 'classification', 'text-matching'
- 配置参数需要注意的是检索用
- jinaai/jina-reranker-m0 · Hugging Face: https://huggingface.co/jinaai/jina-reranker-m0
检索后再做重排。
- 官网:https://jina.ai/
混合检索
数据库搭建
- 数据库搭建中字段配置,相关文档已经写入了备注。
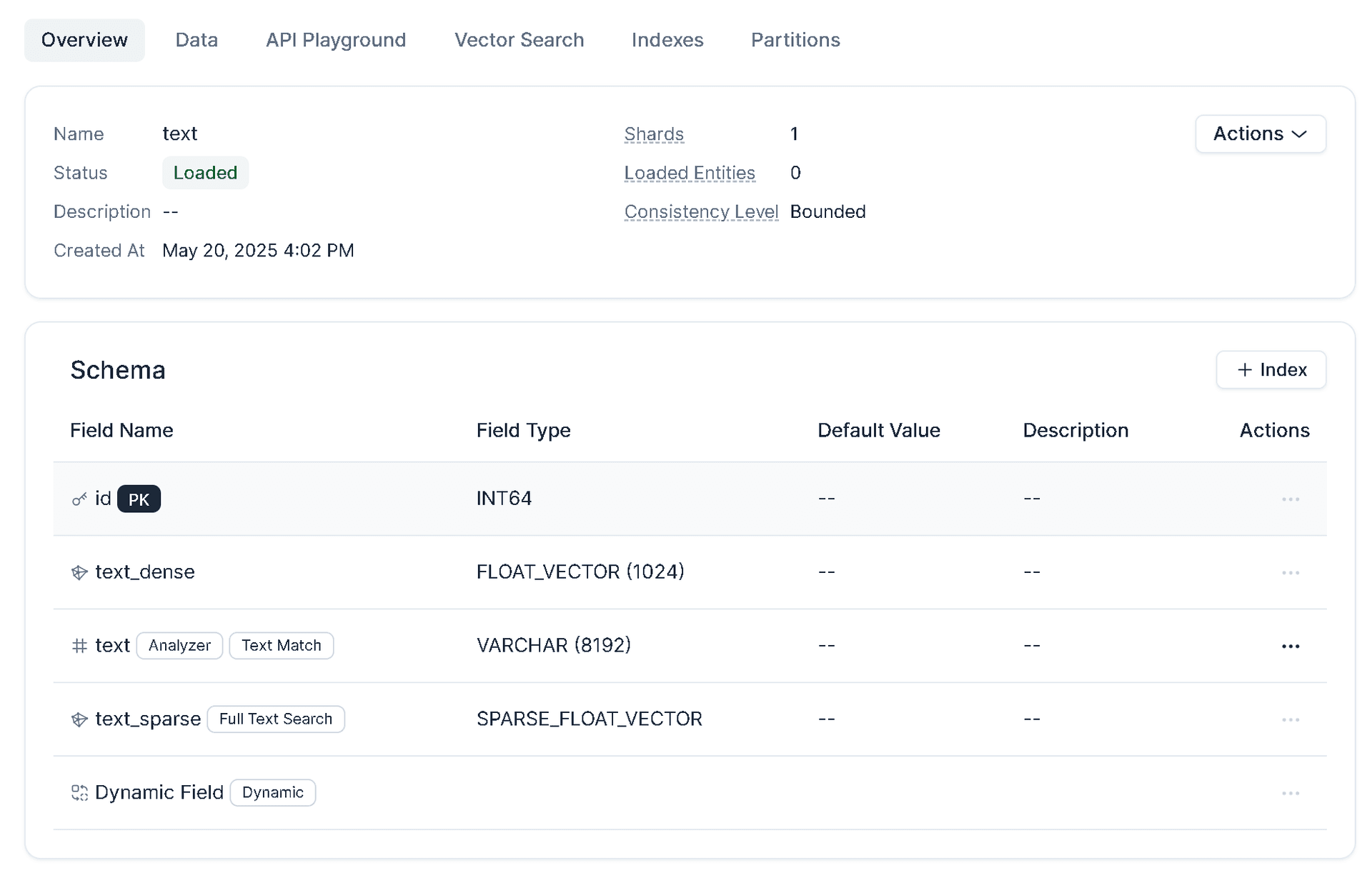
# 创建数据库,配置混合检索、全文搜索、精准文本匹配
from pymilvus import MilvusClient, DataType, Function, FunctionType
client = MilvusClient(
uri="YOUR_CLUSTER_ENDPOINT",
token="YOUR_CLUSTER_TOKEN"
)
# 开启 Dynamic 动态字段:enable_dynamic_field=True
# 关闭 Auto ID:auto_id=False
schema = MilvusClient.create_schema(auto_id=False, enable_dynamic_field=True)
# 全文检索&精确文本匹配:https://docs.zilliz.com.cn/docs/full-text-search
# 配置分词器
# Standard Analyzer 是 Zilliz Cloud 中的默认 Analyzer
# 如果未指定 Analyzer ,它将自动应用于文本字段。它使用基于语法的分词,因此对大多数语言都有效。
analyzer_params = {
"type": "standard"
}
# 关闭 Auto ID,配置自定义 id 方便后续数据的修改
schema.add_field(field_name="id", datatype=DataType.INT64, is_primary=True)
schema.add_field(field_name='text', datatype=DataType.VARCHAR, max_length=8192, analyzer_params = analyzer_params, enable_analyzer=True, enable_match=True)
schema.add_field(field_name="text_dense", datatype=DataType.FLOAT_VECTOR, dim=1024)
schema.add_field(field_name="text_sparse", datatype=DataType.SPARSE_FLOAT_VECTOR)
# 创建一个将文本转换为稀疏向量的 Function
bm25_function = Function(
name="text_BM25",
input_field_names="text", # 包含原始文本数据的 VARCHAR 字段名称
output_field_names="text_sparse", # 存储生成的向量的 SPARSE_FLOAT_VECTOR 字段名称
function_type=FunctionType.BM25,
)
schema.add_function(bm25_function)
# 配置索引参数
index_params = MilvusClient.prepare_index_params()
index_params.add_index(
field_name="text_dense",
index_name="text_dense_index",
index_type="IVF_FLAT",
metric_type="IP",
params={"nlist": 128},
)
index_params.add_index(
field_name="text_sparse",
index_name="text_sparse_index",
index_type="SPARSE_INVERTED_INDEX",
metric_type="BM25"
)
# 创建 Collection
# 一致性水平:https://docs.zilliz.com.cn/docs/consistency-level#set-consistency-level-in-search
client.create_collection(
collection_name='text',
schema=schema,
consistency_level="Bounded",
index_params=index_params
)
检索命令
- Zilliz 文档没更新,混合检索命令只需稠密向量和文本,无需稀疏向量。
# 混合检索:结合全文检索、精确文本匹配: https://docs.zilliz.com.cn/docs/hybrid-search
from pymilvus import MilvusClient, AnnSearchRequest, RRFRanker
client = MilvusClient(
uri="YOUR_CLUSTER_ENDPOINT",
token="YOUR_CLUSTER_TOKEN"
)
query_dense_vector = []
# 向量检索
# 精确文本匹配:和
expr_and = "TEXT_MATCH(text, 'keyword1') and TEXT_MATCH(text, 'keyword2')"
search_param_dense = {
"anns_field": "text_dense",
"data": [query_dense_vector],
"expr": expr_and,
"param": {
"metric_type": "IP",
"offset": 0,
"params": {
"nprobe": 10,
}
},
"limit": 10
}
request_dense = AnnSearchRequest(**search_param_dense)
# 稀疏向量字段全文搜索
sparse_data = ["text1 text2"]
search_param_sparse = {
"anns_field": "text_sparse",
"data": sparse_data,
"param": {
"metric_type": "BM25",
"drop_ratio_search": "0.2"
},
"limit": 5
}
request_sparse = AnnSearchRequest(**search_param_sparse)
reqs = [request_dense, request_sparse]
ranker = RRFRanker(100)
res = client.hybrid_search(
collection_name="text",
reqs=reqs,
ranker=ranker,
limit=10,
output_fields=["id", "text"]
)
for hits in res:
print("TopK results:")
for hit in hits:
print(hit)