- Published on
Database | Zilliz Vector Database Model Selection and Field Construction
CAUTION
This article was translated from Chinese by an AI model and may contain inaccuracies. If you find issues, please refer to the original or suggest corrections.
Problem
- Zilliz Cloud Pipelines has been discontinued, and the backend configuration page (visual...) received a major update (around May 19, release notes not yet updated). Users need to select their own model service provider to rebuild data.

Solution Approach
Vector model selection criteria:
- Can be called online without self-deployment.
- Open source, can be deployed locally, with data vectorized and transmitted to Zilliz cloud.
- Accuracy, lower priority, can use reranker model for secondary filtering.
Model selection challenge: Major vendors' open-source models and online-callable models are not interchangeable.
Selection result: Jina AI
- Official website: https://jina.ai/
Offers free API for testing.
- jinaai/jina-embeddings-v3 · Hugging Face: https://huggingface.co/jinaai/jina-embeddings-v3
- Important configuration parameters: use
retrieval.queryfor retrieval, useretrieval.passagefor long text vectorization max_length=8192truncate_dim Supported dimensions are [32, 64, 128, 256, 512, 768, 1024]task = 'retrieval.query', 'retrieval.passage', 'separation', 'classification', 'text-matching'
- Important configuration parameters: use
- jinaai/jina-reranker-m0 · Hugging Face: https://huggingface.co/jinaai/jina-reranker-m0
Perform re-ranking after retrieval.
- Official website: https://jina.ai/
Hybrid Search
Database Construction
- Field configuration during database construction, relevant documentation has been written in the notes.
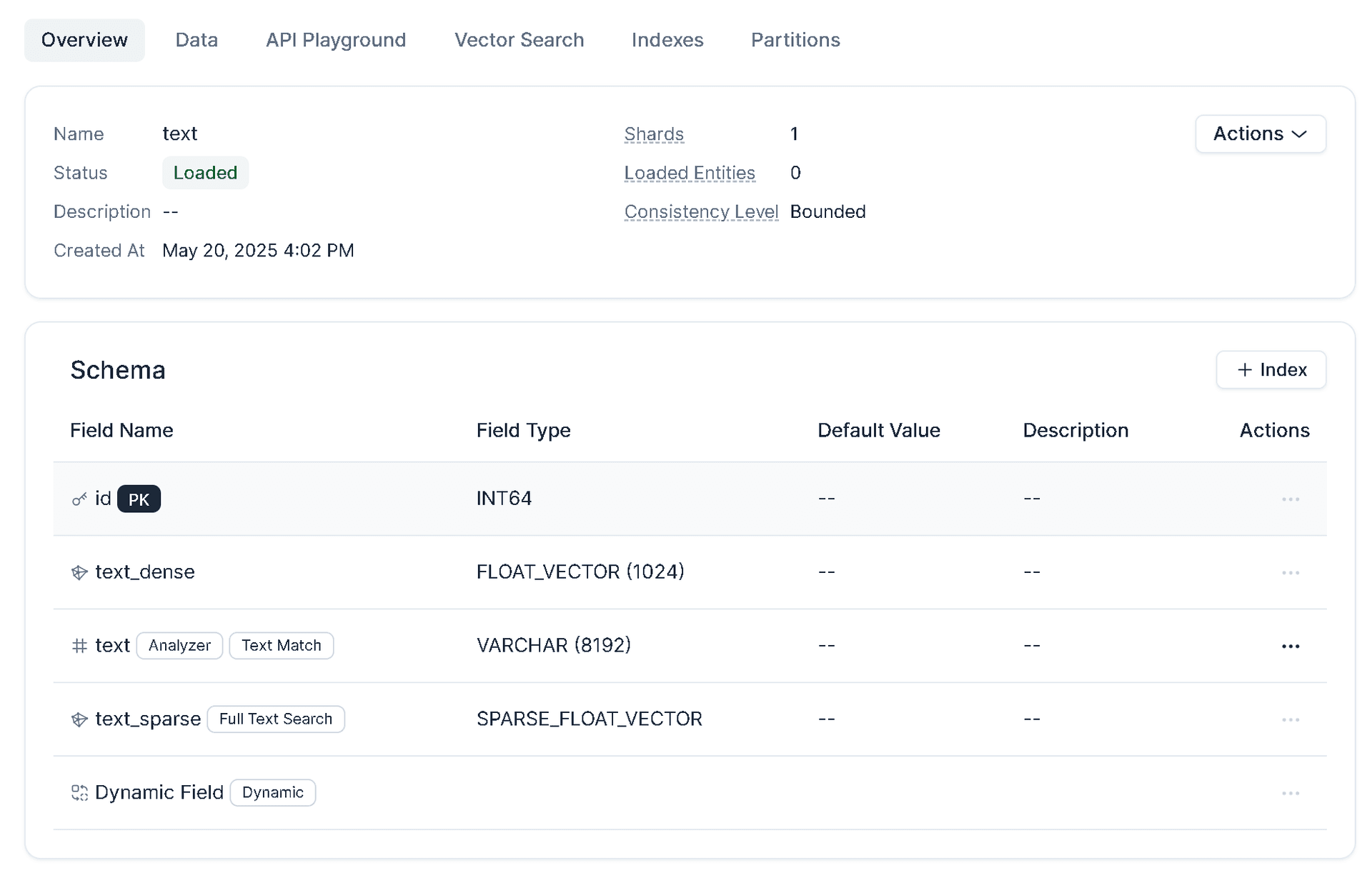
# 创建数据库,配置混合检索、全文搜索、精准文本匹配
from pymilvus import MilvusClient, DataType, Function, FunctionType
client = MilvusClient(
uri="YOUR_CLUSTER_ENDPOINT",
token="YOUR_CLUSTER_TOKEN"
)
# 开启 Dynamic 动态字段:enable_dynamic_field=True
# 关闭 Auto ID:auto_id=False
schema = MilvusClient.create_schema(auto_id=False, enable_dynamic_field=True)
# 全文检索&精确文本匹配:https://docs.zilliz.com.cn/docs/full-text-search
# 配置分词器
# Standard Analyzer 是 Zilliz Cloud 中的默认 Analyzer
# 如果未指定 Analyzer ,它将自动应用于文本字段。它使用基于语法的分词,因此对大多数语言都有效。
analyzer_params = {
"type": "standard"
}
# 关闭 Auto ID,配置自定义 id 方便后续数据的修改
schema.add_field(field_name="id", datatype=DataType.INT64, is_primary=True)
schema.add_field(field_name='text', datatype=DataType.VARCHAR, max_length=8192, analyzer_params = analyzer_params, enable_analyzer=True, enable_match=True)
schema.add_field(field_name="text_dense", datatype=DataType.FLOAT_VECTOR, dim=1024)
schema.add_field(field_name="text_sparse", datatype=DataType.SPARSE_FLOAT_VECTOR)
# 创建一个将文本转换为稀疏向量的 Function
bm25_function = Function(
name="text_BM25",
input_field_names="text", # 包含原始文本数据的 VARCHAR 字段名称
output_field_names="text_sparse", # 存储生成的向量的 SPARSE_FLOAT_VECTOR 字段名称
function_type=FunctionType.BM25,
)
schema.add_function(bm25_function)
# 配置索引参数
index_params = MilvusClient.prepare_index_params()
index_params.add_index(
field_name="text_dense",
index_name="text_dense_index",
index_type="IVF_FLAT",
metric_type="IP",
params={"nlist": 128},
)
index_params.add_index(
field_name="text_sparse",
index_name="text_sparse_index",
index_type="SPARSE_INVERTED_INDEX",
metric_type="BM25"
)
# 创建 Collection
# 一致性水平:https://docs.zilliz.com.cn/docs/consistency-level#set-consistency-level-in-search
client.create_collection(
collection_name='text',
schema=schema,
consistency_level="Bounded",
index_params=index_params
)
Search Commands
- Zilliz documentation not yet updated, hybrid search commands only require dense vectors and text, no sparse vectors needed.
# 混合检索:结合全文检索、精确文本匹配: https://docs.zilliz.com.cn/docs/hybrid-search
from pymilvus import MilvusClient, AnnSearchRequest, RRFRanker
client = MilvusClient(
uri="YOUR_CLUSTER_ENDPOINT",
token="YOUR_CLUSTER_TOKEN"
)
query_dense_vector = []
# 向量检索
# 精确文本匹配:和
expr_and = "TEXT_MATCH(text, 'keyword1') and TEXT_MATCH(text, 'keyword2')"
search_param_dense = {
"anns_field": "text_dense",
"data": [query_dense_vector],
"expr": expr_and,
"param": {
"metric_type": "IP",
"offset": 0,
"params": {
"nprobe": 10,
}
},
"limit": 10
}
request_dense = AnnSearchRequest(**search_param_dense)
# 稀疏向量字段全文搜索
sparse_data = ["text1 text2"]
search_param_sparse = {
"anns_field": "text_sparse",
"data": sparse_data,
"param": {
"metric_type": "BM25",
"drop_ratio_search": "0.2"
},
"limit": 5
}
request_sparse = AnnSearchRequest(**search_param_sparse)
reqs = [request_dense, request_sparse]
ranker = RRFRanker(100)
res = client.hybrid_search(
collection_name="text",
reqs=reqs,
ranker=ranker,
limit=10,
output_fields=["id", "text"]
)
for hits in res:
print("TopK results:")
for hit in hits:
print(hit)
Table of contents
⏳ 4 min read📇 651 words
👁️ --- views
📅 Published on: May 20, 2025
Sort:
0 commentsNo comments yet. Be the first!